






浏览 3.1k
概述
NGINX速率限制是一个很重要的流量管理模块,用来限制单位时间的请求数。通过正确有效地配置,特定客户端对某一个URI的访问频率频率可以得到有效地限制, 从而可以有效地减缓暴力密码破解攻击,也可以有效减缓DDOS攻击的破坏性,还可以防止上游服务器被大量并发的请求耗尽资源。
本篇文章我们就速度限制功能的原理和源代码进行解析,从而可以更好地理解和使用速度限制功能。
原理
漏桶(Leaky Bucket)算法和令牌桶(Token Bucket)算法被广泛使用于通信领域进行流量整形和速率控制。NGINX采用的是漏桶(Leaky Bucket)算法来实现速率控制。
漏桶(Leaky Bucket)算法思路很简单。我们可以把用户请求比做水先进入到漏桶里,漏桶以一定的速度出水(处理请求),当水流入速度过大会直接溢出(访问频率超过接口响应速率),然后就拒绝请求。可以看出漏桶算法能强行限制数据的传输速率。
使用一幅经典的图片来解释漏桶算法的原理:
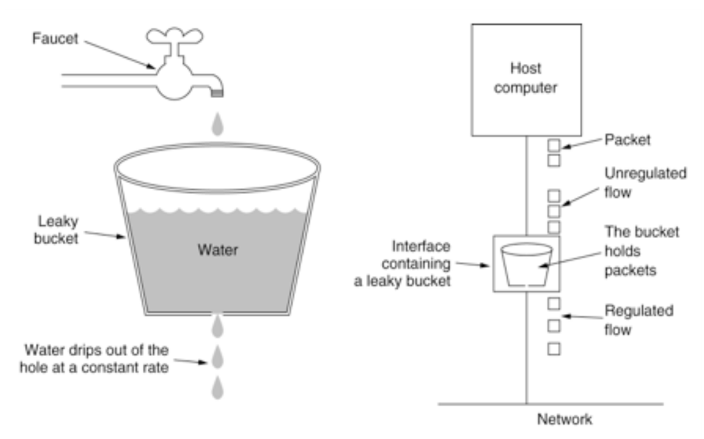
使用伪代码来表示漏桶算法就是:
int speed; //处理请求的速率,比如2r/s表示每秒处理2个请求
int requests; //当前系统的请求个数
int bucket; //系统的漏桶大小
time_t last_process_time; //上一次处理请求时间
int processed = 0;
/*当一个请求到达系统以后,计算从上一次处理请求到现在为止这段时间一共可以处理多少个请求。然后再计算系统当前未处理请求个数为多少。如果未处理的请求个数小于bucket大小,说明可以继续处理当前请求。反之,要把当前请求丢弃掉。*/
processed = (get_now_time() - last_porcess_time) * speed;
remain_requests = max(0, requests - processed);
last_process_time = get_now_time();
If (remain_requests < bucket ) {
requests = remain_requests ++;
return “可以处理请求”;
} else {
return “丢弃请求,不处理”;
}
配置语法
NGINX通过limit_req_zone和limit_req两条指令来实现速率限制。指令limit_req_zone定义了限速的参数,指令limit_req在所在的location使能定义的速率。
指令limit_req_zone
配置语法:
Syntax:limit_req_zone key zone=name:size rate=rate;
Default:—
Context:http
参数key定义了基于什么样的参数进行速率控制。比如下面的例子中的$binary_remote_addr就是表示使用客户端的ip地址(remote_addr)进行速率控制。而且为了节省存储空间采用了二进制的表示方式。
参数zone定义一块共享内存区域。这片共享内存用来存储每一个ip地址的状态以及每个ip访问特定URL的频率。因为采用了共享内存的方式(关于NGINX共享内存可以参考这篇文章),所以,这些信息可以被所有的worker进程共用。通过此参数可以定义共享内存的名字和大小。指令limit_req通过这个共享内存的名字来对某一个URI进行速率控制。对于zone的大小,一般是每1M大小的空间可以存储16K不同客户的状态信息。当内存空间耗尽,再来新的连接时,会把最老的状态信息释放用来存储新的连接信息。而且,为了尽量防止zone空间被消耗空,NGINX每次创建新的状态信息时,会尝试删除几个前60秒内没有被使用的空间。
参数rate定义了最终要控制的速率。可以按秒为单位比如10r/s也可以按分钟为单位比如600r/m进行配置。最终NGINX会把所有的参数统一为按秒为单位。所以10r/s和600r/m效果是一样的。在最终的代码实现中,NGINX会以每一个请求间隔多少ms为单位进行控制。比如10r/s表示一秒只允许10个请求,也就是每100 ms允许一个请求。在这种情况下,如果处理完一个请求后,在100ms内到达的请求都会被丢掉。当然如果配置了burst参数效果会有不同。关于burst参数我们在指令limit_req中介绍。
指令limit_req
配置语法如下:
Syntax:limit_req zone=name [burst=number] [nodelay | delay=number];
Default:—
Context:http, server, location
指令limit_req_zone定义了速率限制的参数。通过制定limit_req可以把定义的参数应用到所述的http, server或者location上下文中。
参数zone指明了要使用的哪一个limit_req_zone定义的参数。
参数burst用来处理突发请求。在上述limit_req_zone的例子中,任何在100ms之内到达的请求都对被丢弃掉。通过burst参数,可以定义个特定大小的queue,比如10。当一个请求早于100ms到达的请求可以先存放到queue中。如果queue满了,后续的请求都会被丢掉。然后对queue中的请求再按照100ms的频率去处理。
参数nodelay表示对于queue中的请求要立刻发送出去。默认不添加nodelay参数情况下queue中的请求会按照规定的速率比如100ms一个发送出。虽然queue中的请求被立刻发出去,但是queue中每一个请求对应的槽位只有在特定时候以后,我们的例子中是100ms,才能再次被使用。按照我们的例子,burst是10, 假如此时系统中10个burst槽位都是可以使用的,这是同时有20个请求到达,NGINX此时会立刻转发前11个请求(1+10 burst),同时会标注这10个burst定义的槽位不可以使用。同时对后面9个请求全部返回503状态。然后NGINX每隔100ms会释放一个burst槽位给后续请求使用。假如发送完前11个请求以后,再过了101ms,此时又连续达到20个请求,因为只有一个槽位可用,所以,NGINX会只转发1个请求,把剩余的19个请求全部返回503。假如转发完这一个请求后再过了501ms后又连续到达20个请求,因为501ms可以释放5个burst定义的槽位,所以此时NGINX会连续转发5个请求,然后对后面的15个请求返回状态503。这样运行整体的效果也会符合limit_req_zone定义的100ms处理一个请求的限制。
参数delay用来对流量进行两个阶段控制。配置了delay参数以后,比如配置limit_req zone=name burst=10 delay=3控制的效果是,对于burst中的10个请求,前面的10-3=7个请求按照nodelay的方式立刻发送出去。对于后面3个请求,按照指令定义的速率进行发送。
除了limit_req_zone和limit_req这两个功能指令以外,还有下列一些辅助指令。
指令limit_req_dry_run
Syntax:limit_req_dry_run on | off;
Default:
limit_req_dry_run off;
Context:http, server, location
使能演习(dry run)模式。在这种模式下,只会把请求的状态信息保存在共享内存中,限速功能不会生效。
指令limit_req_log_level
Syntax:limit_req_log_level info | notice | warn | error;
Default:
limit_req_log_level error;
Context:http, server, location
设置与限速功能相关的log级别。比如设置为limit_req_log_level notice 则限速相关的log会按照notice的级别进行记录。
指令limit_req_status
Syntax:limit_req_status code;
Default:
limit_req_status 503;
Context:http, server, location
设置NGINX拒绝连接请求时发送给客户端的HTTP代码,默认是503。
配置说明
一个location块中可以配置多条limit_req指令。当符合请求的所有限制都被应用时,将采用最严格的那个限制。例如,多条匹配指令中有一条要拒绝这个请求,那么这个请求就被拒绝。如果匹配的指令都制定了延迟,将采用最长的那个延迟。
比如:
http {
limit_req_zone $uri zone=req_zone:10m rate=5r/s;
limit_req_zone $binary_remote_addr zone=req_zone_wl:10m rate=15r/s;
server {
location / {
limit_req zone=req_zone burst=10 nodelay;
limit_req zone=req_zone_wl burst=20 nodelay;
}
}
}
如果请求只会匹配到其中某一条limit_req,则按照匹配到的限速参数进行限速。如果两个限制能匹配到,则应用限制更强的每秒5个请求那个。
另外限速模块还可以和别的模块比如geo和map一起实现很多高级功能,比如只针对特定客户进行限速等等。
配置效果测试
现在我们通过实验来验证NGINX在不同的配置情况下的速率限制行为。
测试环境
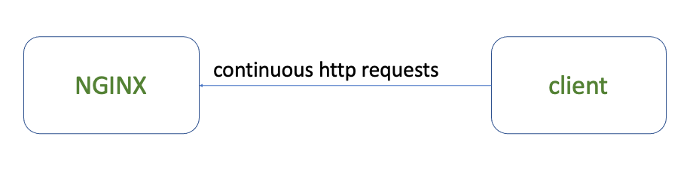
客户端通过脚本发送HTTP请求到jikui.test.com服务器的path1路径上,然后我们通过NGINX服务器的access.log来观察NGINX在不同的配置策略下的处理行为,从而可以更深入地了解各个参数的含义。
用来发送HTTP请求的脚本存放在https://github.com/pei-jikui/limit_req中。
场景1
指令limit_req_zone定义了一个大小是10m的名称为one的区域用来根据客户端地址存储状态信息,然后速率的控制是每秒5个请求。
指令limit_req通过limit_req zone=one; 在服务器jikui.test.com的path1 URI中使能了上述速率限制定义。
http {
limit_req_zone $binary_remote_addr zone=one:10m rate=5r/s;
server {
server_name jikui.test.com;
location path1 {
limit_req zone=one;
}
}
}
预期的效果是,NGINX每200ms处理一个HTTP请求。对于200ms之间的请求都会返回503。
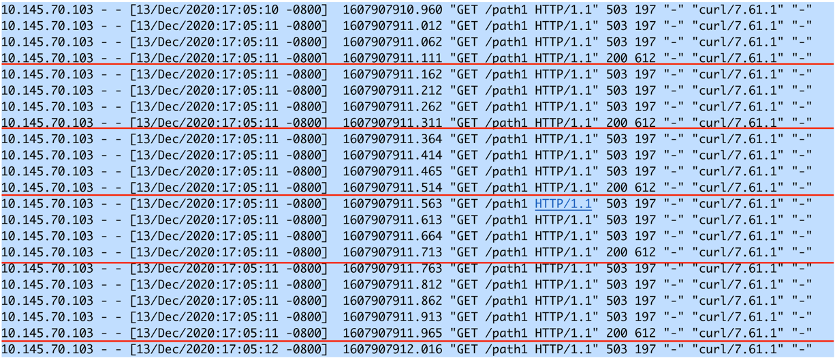
观察log文件我们可以看到在17:05:11秒这一秒内按照每200ms一个的速率处理了5个请求,然后对于所有的200ms之间的请求都返回了503。
场景2
指令limit_req添加burst参数通过limit_req zone=one burst=10; 在服务器jikui.test.com的path1 URI中使能了上述速率限制定义。
http {
limit_req_zone $binary_remote_addr zone=one:10m rate=5r/s;
server {
server_name jikui.test.com;
location path1 {
limit_req zone=one burst=10;
}
}
}
指令limit_req通过limit_req zone=one burst=10; 在服务器jikui.test.com的path1 URI中使能了上述速率限制定义而且定义了突发处理的容量是10。
预期的效果是,对于前11个请求后按照每200ms处理一个的速率进行处理。然后从第12个请求开始到下一个200ms期间(等待burst queue里面的槽位可以使用才可以处理新的请求)的所有请求都返回503。
通过把request的顺序作为脚本中curl命令的agent_name参数进行发送,我们可以从log中清楚地看到NGINX处理请求的行为。
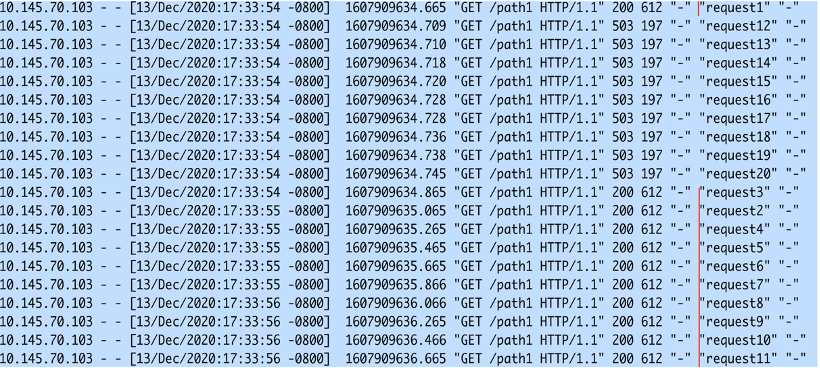
我们可以看到,NGINX先处理request1,然后把request2-request11这10个request先queue起来。然后按照200ms的速率进行处理。对于request12到request20直接返回503。
场景3
指令limit_req添加burst和nodelay参数,通过limit_req zone=one burst=10 nodelay; 在服务器jikui.test.com的path1 URI中使能了上述速率限制定义。
http {
limit_req_zone $binary_remote_addr zone=one:10m rate=5r/s;
server {
server_name jikui.test.com;
location path1 {
limit_req zone=one burst=10 nodelay;
}
}
}
指令limit_req通过limit_req zone=one burst=10 nodelay; 在服务器jikui.test.com的path1 URI中使能了上述速率限制定义而且定义了突发处理的容量是10。而且对于这些突发的请求,不再按照200ms的节奏去处理,而且立刻(nodelay)发送出去。
预期的效果是,对于前11个请求后会立刻进行处理。然后从第12个请求开始到下一个200ms期间(等待burst queue里面的槽位可以使用才可以处理新的请求)的所有请求都返回503。等发送第一个burst中的请求后200ms,NGINX又可以处理新的请求。
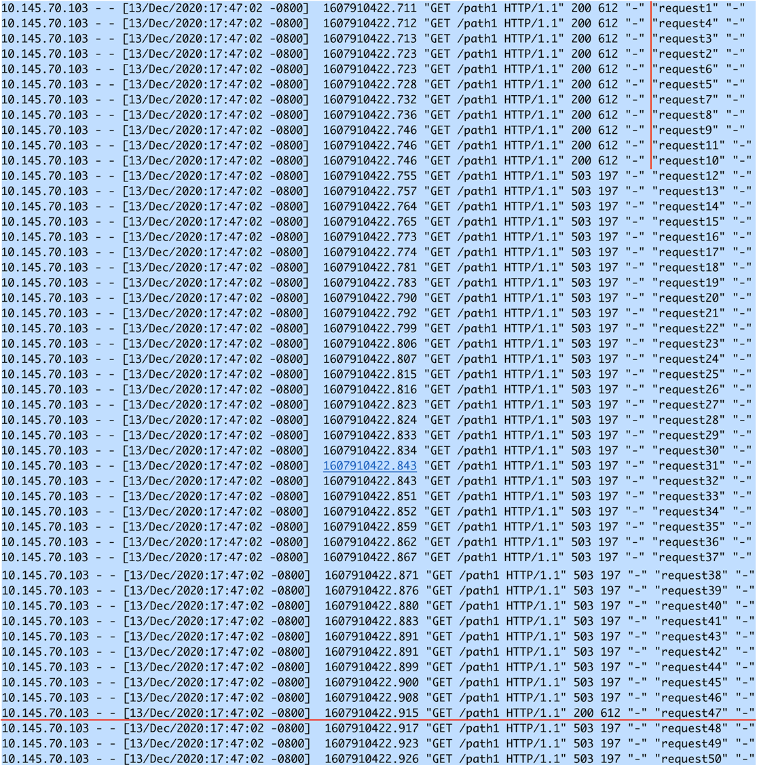
从log中我们可以看到,对于前11个请求,NGINX立刻进行了处理。然后在从处理第一个request之后的200ms之间(等待queue的第一个槽位可用),所有的请求都返回了503,然后200ms以后,queue的槽位有效以后立刻就可以再处理新的请求了。
场景4
指令limit_req添加burst和delay参数,通过limit_req zone=one burst=10 delay=3; 在服务器jikui.test.com的path1 URI中使能了上述速率限制定义。
http {
limit_req_zone $binary_remote_addr zone=one:10m rate=5r/s;
server {
server_name jikui.test.com;
location path1 {
limit_req zone=one burst=10 delay=3;
}
}
}
指令limit_req通过limit_req zone=one burst=10 nodelay; 在服务器jikui.test.com的path1 URI中使能了上述速率限制定义而且定义了突发处理的容量是10。而且对于这些突发的10个请求,分两个阶段进行处理。第一个阶段前3个(delay参数定义的数量)立刻发送出,然后后面10-3=7个请求按照定义的速率每200ms处理一个。
预期的效果是,对于前11个请求中1+3=4个后会立刻进行处理。然后从第5-11个请求会按照200ms的速率进行处理。期间(等待burst queue里面的槽位可以使用才可以处理新的请求)的所有请求都返回503。等发送第11个请求处理完毕200ms后,NGINX又可以处理新的请求。
为了减小图片的大小,只列出了被接收处理的请求。从request4和request5开始每两个请求之间是200ms,这每个200ms之间的请求都会返回503。
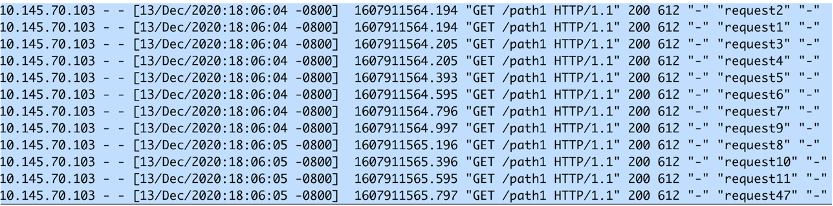
从log可以看到,前面4个请求立刻得到了处理。然后后面的5-11个请求按照200ms的间隔进行处理。第47个请求是在第11个请求完成200ms后被处理的。
场景5
对于一个location添加多条limit_req不同速率控制的指令。为了演示效果,我们采用相同的key值。
http {
limit_req_zone $binary_remote_addr zone=one:10m rate=5r/s;
limit_req_zone $binary_remote_addr zone=two:10m rate=1r/s;
server {
server_name jikui.test.com;
location path1 {
limit_req zone=one;
limit_req zone=two;
}
}
}
对于每一个请求都会匹配到两条速率控制指令,控制更严格的每秒1个请求的指令将会被使用。

从log中我们可以看到,NGINX每秒放行一个请求。当然为了减小log的数量我们没有显示在每一秒之间所有被拒绝的请求。
源码分析
本节,我们从源代码角度去分析速率控制功能是如何实现的。
控制平面
速率控制主要是通过limit_req_zone和limit_req两条指令完成的。在NGINX的启动阶段对这两条指令进行解析。
指令limit_req_zone解析流程:
- 解析指令limit_req_zone 的函数为ngx_http_limit_req_zone。它会首先解析key属性以及zone的名称和大小参数,然后通过函数ngx_shared_memory_add 申请一片共享内存。在解析参数rate时,会把速率定义统一转换成每秒处理多少请求。并且把函数ngx_http_limit_req_init_zone 设置为这片共享内存的初始化函数。
- NGINX解析完成以后,会生成系统申请的共享内存,并且调用对应的初始化函数进行初始化。对于为速率限制生成的内存会调用ngx_http_limit_req_init_zone完成初始化工作。
- 函数ngx_http_limit_req_init_zone会把上述的共享内存区域初始化为红黑树用来存储客户连接信息。
指令limit_req解析流程:
- 解析指令limit_req的函数为ngx_http_limit_req。
- 函数主要的工作是解析burst, nodelay和delay参数。对于nodelay参数会转换成一个NGX_MAX_INT_T_VALUE常数。然后生成一个ngx_http_limit_req_limit_t结构中。
- 然后把上述的ngx_http_limit_req_limit_t结构存放到ngx_http_limit_req_conf_t结构中的limits数组中。这个数组存放的某一个location中所有定义的limit_req。
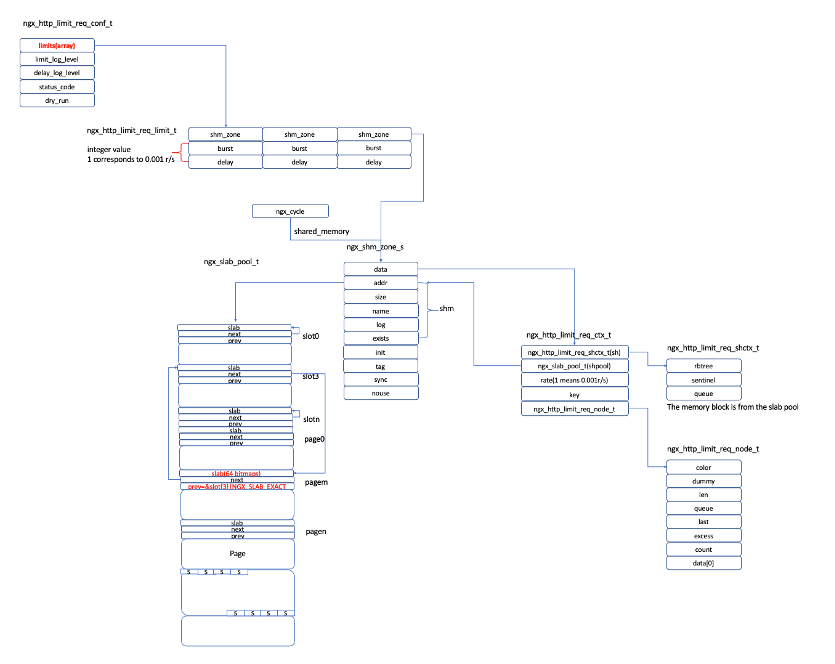
指令解析完毕以后相关数据结构的关系如下图所示:
数据平面
NGINX速率限制对应的模块是ngx_http_limit_req_module,它处于HTTP的11个处理阶段的NGX_HTTP_PREACCESS_PHASE阶段,处理函数是ngx_http_limit_req_handler。
我们忽略NGINX是如何处理HTTP请求的,直接从函数ngx_http_limit_req_handler的处理逻辑开始分析。
- 函数ngx_http_limit_req_handler首先会通过http_request结构得到结构ngx_http_limit_req_conf_t,对应上面数据结构中左上角的部分。
- 然后遍历ngx_http_limit_req_conf_t结构中所有的limits数组元素(limits数组中每一个元素对应location中一条limit_req指令)。对于每一个数组元素计算对应的key值,然后调用函数ngx_http_limit_req_lookup 进行匹配。
- 如果函数ngx_http_limit_req_lookup返回的匹配结果是NGX_DECLINED,表示没有限速规则,则进入下一个handler进行处理。
- 如果匹配结果是NGX_ERROR或者是NGX_BUSY,表示出错。直接返回503或者配置的状态码。
- 如果接受了当前的处理请求,调用函数ngx_http_limit_req_account来计算对当前请求处理delay的时间。
- 计算出delay时间以后,把当前的http_request的读写回调函数分别设置为ngx_http_test_reading和ngx_http_limit_req_delay。然后通过ngx_add_timer把当前http_request加入到NGINX的TIMER系统中。当delay数量的时间到期,回调函数ngx_http_limit_req_delay就会得到调用。
函数ngx_http_limit_req_lookup的逻辑是:
- 简单来说,函数ngx_http_limit_req_lookup的目的就用来判断当前的limit是可以处理当前的请求还是需要把当前请求丢弃。
- 函数ngx_http_limit_req_lookup查找对应当前的http_request的匹配结果。NGX_BUSY表示严重超配,已经超出burst阈值,需要返回错误码。 NGX_OK 表示本规则超配,需要延迟处理。NGX_AGAIN 本规则没有超配,要检测下一个规则。
- 根据key值在红黑树中查找是否已经已有对应节点存在。如果已经存在,则根据节点的excess以及配置的速率参数,计算从上次请求到现在系统还会有多少请求没有处理。如果没有处理到的请求数量大于配置的burst数量,表明不能处理当前请求。则返回NGX_BUSY。
- 反之,如果系统可以处理当前请求,并且查询的是location最后一个limit_req定义的规则,则返回NGX_OK。如果不是最后一个,则返回NGX_AGAIN继续查找下一个limit_req规则。
- 如果key值对应的节点在当前的红黑树中不存在,则生成一个key值节点插入到红黑树中。调用函数ngx_http_limit_req_expire来回收红黑树中1到2个已经超过60秒没有被引用,也没有限速的节点。
- 在生成新节点申请slab中内存时,如果申请失败则会调用函数ngx_http_limit_req_expire尽量释放没有被引用的老的内存块。
函数ngx_http_limit_req_account的逻辑是:
- 简单地说,函数ngx_http_limit_req_account是在NGINX决定已经可以处理当前请求了,然后使用此函数计算需要延迟多久来处理这个请求。
- 遍历所有的limits数组中的元素,利用漏桶算法计算出每一个命中的limit元素中最大的delay数量。然后返回delay的最大值。
函数ngx_http_limit_req_delay的逻辑是:
- 函数ngx_http_limit_req_delay是针对请求的延时处理函数。
- 当delay的时间到期,函数得到运行时,会再次运行ngx_http_core_run_phases,执行HTTP的11个阶段。
结语
速率控制是NGINX流量管理功能中一个很重要的模块,通过它可以有效地保护上游服务器的安全和减缓上游服务器的负载。只有深入理解配置的几个参数比如burst, nodelay, delay的意义后才能正确的使用它。希望这篇文章能对您有所帮助。下篇我们将分析并发控制模块的使用和原理。


按点赞数排序
按时间排序
您好,我的nginx的限流配置为limit_req_zone $binary_remote_addr zone=reqconsole1:100m rate=1000r/s;我修改limit_req_zone的key从binary_remote_addr为client_real_ip,在reload nginx进程时error日志报错limit_req "reqconsole" uses the "$client_real_ip" key while previously it used the "$binary_remote_addr" key。并且nginx reload并不生效
请问这个和nginx的共享内存在reload时不释放引起的吗?
 赞同
赞同0
 回复
回复 举报
举报发表于2022-09-12 10:59


 点赞 1
点赞 1 浏览 3.5k点赞 0浏览 1.3k点赞 0浏览 474
浏览 3.5k点赞 0浏览 1.3k点赞 0浏览 474
 微信公众号
微信公众号 加入微信群
加入微信群

