





浏览 1.4k
无意之间 突发奇想,设置如下nginx conf
upstream upserver {
server 127.0.0.1:12349;
### keepalive 100;
}
server {
listen 12347;
location /hello {
proxy_pass http://upserver;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
即upstream关闭 keepalive,但是server里明确指定 HTTP 1.1协议
通过tcpdump抓包可以看到nginx端使用HTTP 1.1协议请求upstream server,请求完毕之后发送FIN包关闭连接了!!!
这是什么原因呢? 百思不得其解,网络也没有这个问题的明确解答,源码里也找不到相应的代码逻辑之处

按点赞数排序
按时间排序
proxy_http_version为1.1,同时Connection: keep-alive,这只是说:HTTP协议是支持长连接的。但客户端要不要使用长连接呢?如果使用长连接,就得有连接池,那么连接池应该是多少呢?毕竟一旦有连接池,就可能存在资源浪费,在用户没有明确的配置keepalive连接池时,Nginx还是不会使用长连接。
 赞同
赞同1
回复 举报
举报回答于2020-09-10 11:41

翻了好久的nginx源码,大概清晰了。
ngx_http_upstream.c文件 ngx_http_upstream_finalize_request函数
if (u->peer.connection) { // 如果upstream peer connection不为null,则会关闭连接
ngx_close_connection(u->peer.connection);
}
ngx_http_upstream_keepalive_module.c文件 ngx_http_upstream_free_keepalive_peer函数
ngx_queue_insert_head(&kp->conf->cache, q); // 将free数组里的连接 放回到cached数组里
pc->connection = NULL; // 如果配置了keepalive属性,此时会将connections设置为null,避免被 ngx_http_upstream_finalize_request() 关闭连接
ngx_http_upstream_round_robin.c文件 ngx_http_upstream_free_round_robin_peer函数
没有对connection做任何设置,connection不为null
赞同0
回复举报回答于2020-09-11 11:26


知乎上找来的答案啊
先说结论:Nginx要搞自己的Service Mesh
去年IBM伙同Google和Lyft一起开源了微服务治理项目Istio。工作原理很简单:
- 利用Kubernetes的Pod机制,在每个业务容器所在的Pod里自动注入一个Envoy容器
- Envoy容器接管业务容器的所有进出流量
- 这样Istio的控制平面(Control Plane)通过操作Envoy容器来实现一系列微服务治理的功能比如:
- 蓝绿发布
- 流量切分
- 授权
- 策略配置
- (反正就是各种配置Envoy这个代理而已……)
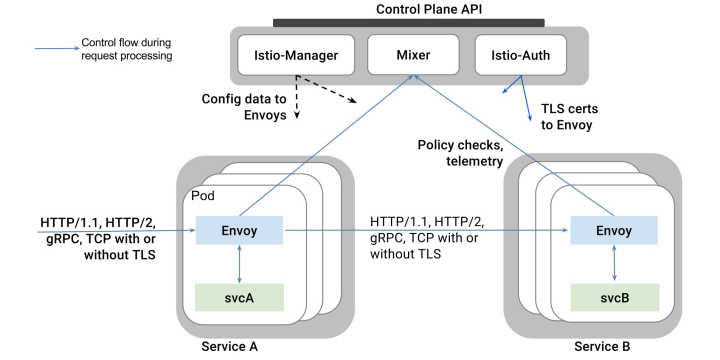
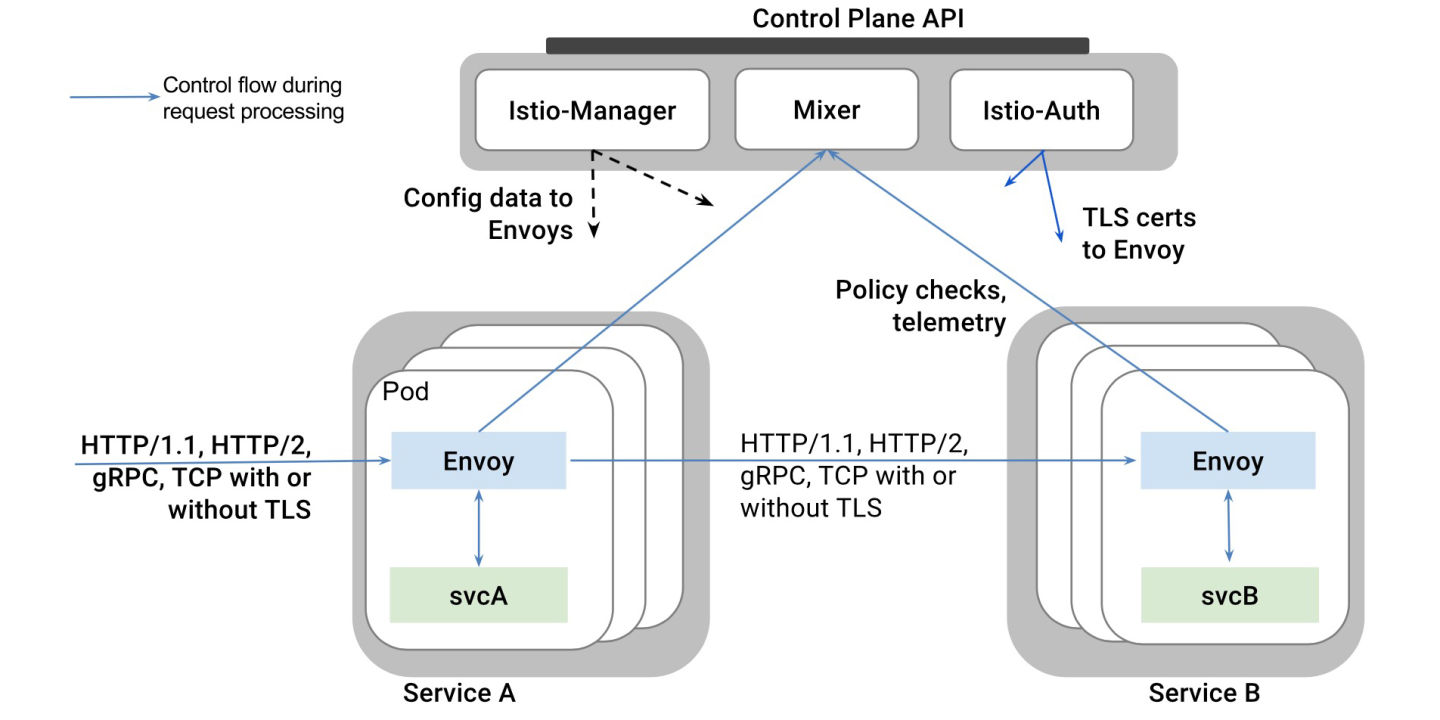
这个项目巧妙地利用了Kubernetes推崇的容器化设计模式(Pod + 自动注入容器)实现了非常优雅的流量接管,打脸了一票Mesos党(雾)。又借助Google站台和跟Kubernetes原生绑定(虽然不lock),很快打开了云服务市场。而此时,类似的服务治理能力在容器化集群中还是一片空白呢。
有意思的是,Lyft在整个项目中,实际上就贡献了一个Envoy。但相比Nginx那一坨配置和插件,Envoy的好处很明显:基于API的配置方式,grpc+http2,非常适合作为容器部署。所以伴随着Istio的大热,Envoy很快就火了,不仅在各大公司里都有了落地,还有很多从Nginx迁移到Envoy的案例刷刷地冒了出来(比如:https://blog.turbinelabs.io/our-move-to-envoy-bfeb08aa822d),很多startup甚至一上来就直接选Envoy来做proxy了。
这,就让Nginx很尴尬了。
所以Nginx先是做了个Nginx Mesh,其实就是把上图中的Envoy容器换成了Nginx容器。无奈Nginx实在是太“原始”了,尤其是配置太难用了。所以这次的Unit,其实就是按照Envoy的模式重新做了一个方案,从而让Nginx真正有能力去扛Service Mesh的大旗。这么看,它的三个关键特性就很容易理解了:
Multi-language support = 方便部署
Programmable = 基于API的配置方式
Service mesh = 支持Istio的现有功能
当然,要想直接撼动Istio现在的地位还是很难的。所以可能也会先考虑跟Istio集成,然后可以再发布一套类似的方案?毕竟这一块大家目前都走的不远,还有一大票优化、特性可以做呢。
其他回答里有说没啥卵用的,这东西你单机装一个玩必然没啥卵用。不妨把咱那套Kubernetes集群上的灰擦一擦?
 点赞 0
点赞 0 浏览 1k
浏览 1k没有回答,我就只能自己回答了。
查了下代码,进行gdb跟踪调试后发现:这个主要是因为,每个worker单独维护一个前后端 “链路”关联的四元组信息,在多个worker的情况下,不同的worker保存“链路”关联信息相互独立,彼此不共享。因此即使是相同的IP和端口发来的消息,只要是分配到不同的worker进行处理,都有可能查不到之前的“链路”关联信息,从而无法复用。
解决办法:
1. 单worker配置(性能可能偏低)
2. 修改代码,使用共享内存保存已有的前后端“链路”关联信息,不同worker之间共享结果
点赞 0浏览 412
 微信公众号
微信公众号 加入微信群
加入微信群

