






浏览 1.3k
本文是容器技术系列文章的一部分:
- Namespace 和 cgroup 简介及其工作原理(本文)
我最近一直在研究开源多语言应用服务器 NGINX Unit。在研究中,我注意到 Unit 同时支持 namespace 和 cgroup 这两项进程隔离的特性。本文将介绍这两大构成容器基础的 Linux 技术。
容器及相关工具(例如 Docker 和 Kubernetes)出现有一段时间了。它们改变了现代应用环境中软件的开发和交付方式。容器可支持软件在各自的隔离环境中快速部署和运行,而无需用户构建单独的虚拟机 (VM)。
大多数人可能很少考虑容器的工作基础,但我认为,了解底层技术很重要,因为这有助于我们制定决策。另外,就我个人而言,能够彻底弄清事物的工作原理令我心情舒畅!
什么是 Namespace?
那么,namespace 到底是什么呢 ?百度百科 是这样定义的:
换句话说,namespace 的关键特性是进程隔离。在运行许多不同服务的服务器上,将各个服务及其相关进程相互隔离能够减少变更带来的影响以及安全性方面的问题。大多数情况下,隔离服务符合 Martin Fowler 所描述的微服务架构风格。
Namespace 的类型
- user namespace 拥有自己的一组用户 ID 和组 ID,用于分配给进程。这意味着进程可以在其 user namespace 中拥有 root 权限,而不需要在其他 user namespace 中获得。
- process ID (PID) namespace 将一组 PID 分配给独立于其他 namespace 中的一组 PID 的进程。在新的 namespace 中创建的第一个进程分得 PID 1,子进程被分配给后续的 PID。如果子进程使用自己的 PID namespace 创建,则它在该 namespace 中使用 PID 1,在父进程的 namespace 中使用自己的 PID。请参见下面的示例。
- network namespace 拥有独立的网络栈:自己的专用路由表、IP 地址集、套接字列表、连接跟踪表、防火墙及其他网络相关资源。
- mount namespace 拥有一个独立的挂载点列表,并对该 namespace 中的进程可见。这意味着您可以在 mount namespace 中挂载和卸载文件系统,而不会影响主机文件系统。
- interprocess communication (IPC) namespace 拥有自己的 IPC 资源,例如 POSIX 消息队列。
- UNIX Time‑Sharing (UTS) namespace 允许单个系统对不同的进程显示不同的主机名和域名。
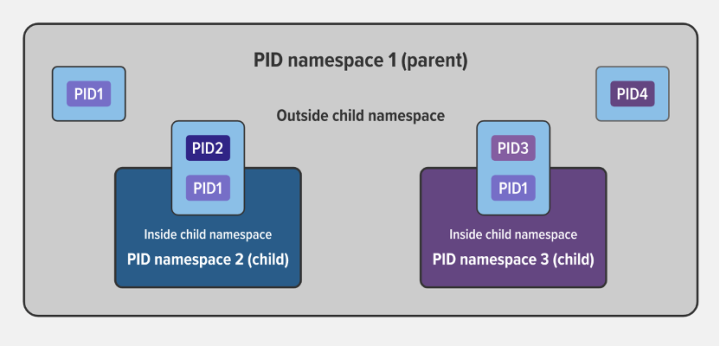
父子 PID Namespace 示例
父 namespace 中使用 PID2 和 PID3 的子进程也属于它们各自的 PID namespace(PID 为 1)。在子 namespace 中,PID1 进程看不到任何外部资源。例如,两个子 namespace 中的 PID1 看不到父 namespace 中的 PID4。
在这种情况下,这使得不同 namespace 中的进程之间得以隔离。
创建 Namespace
NAME
unshare - run program in new name namespacessvk $ id
uid=1000(svk) gid=1000(svk) groups=1000(svk) context=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c.1023svk $ unshare --user --pid --map-root-user --mount-proc --fork bashps -ef 命令显示有两个进程正在运行(bash 和 ps 命令本身),并且 id 命令确认我在新的 namespace 中是root 用户(这一点也可以从更改的命令提示符看出):
root # ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 14:46 pts/0 00:00:00 bash
root 15 1 0 14:46 pts/0 00:00:00 ps -ef
root # id
uid=0(root) gid=0(root) groups=0(root) context=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c.1023从外部角度看 Namespace
输出结果显示了三个 namespace(类型为 user、mnt 和 pid),对应我上面运行的 unshare 命令中的参数。从这个外部角度来看,每个 namespace 都以用户 svk身份运行,而不是以 root身份。而在 namespace 内部,进程以 root 身份运行,并可以访问所有预期的资源。(为了便于阅读,输出结果分成了两行。)
root # lsns --output-all | head -1; lsns --output-all | grep svk
NS TYPE PATH NPROCS PID PPID ...
4026532690 user /proc/97964/ns/user 2 97964 97944 ...
4026532691 mnt /proc/97964/ns/mnt 2 97964 97944 ...
4026532692 pid /proc/97965/ns/pid 1 97965 97964 ...
...COMMAND UID USER
... unshare --user --map-root-user --fork –pid --mount-proc bash 1000 svk
... unshare --user --map-root-user --fork –pid --mount-proc bash 1000 svk
... bash 1000 svkNamespace 和容器
什么是 cgroup?
cgroup 具有以下特性:
- 资源限制 —— 您可以配置 cgroup,从而限制进程可以对特定资源(例如内存或 CPU)的使用量。
- 优先级 —— 当资源发生冲突时,您可以控制一个进程相比另一个 cgroup 中的进程可以使用的资源量(CPU、磁盘或网络)。
- 记录 —— 在 cgroup 级别监控和报告资源限制。
- 控制 —— 您可以使用单个命令更改 cgroup 中所有进程的状态(冻结、停止或重新启动)。
下图说明了当您将特定比例的可用系统资源分配给一个 cgroup(在本例中,为cgroup‑1)后,剩余资源是如何在系统上其他 cgroup(以及各个进程)之间进行分配的。

Cgroup 版本
v2版本的接口也有所更新,其中我最喜欢的是 pressure stall information (PSI)。与之前相比,它能够更精细地提供对每个进程内存使用和分配情况的洞察(不在本博客的讨论范围内,但这是一个非常有意思的话题)。
创建 cgroup
root # mkdir -p /sys/fs/cgroup/memory/foo
root # echo 50000000 > /sys/fs/cgroup/memory/foo/memory.limit_in_bytes我在后台启动 test.sh,脚本生成其输出结果, PID 为 2428,然后我将其 PID 写入 cgroup 文件 /sys/fs/cgroup/memory/foo/cgroup.procs,从而将该进程分配给 cgroup。
root # ./test.sh &
[1] 2428
root # cgroup testing tool
root # echo 2428 > /sys/fs/cgroup/memory/foo/cgroup.procsroot # ps -o cgroup 2428
CGROUP
12:pids:/user.slice/user-0.slice/\
session-13.scope,10:devices:/user.slice,6:memory:/foo,...默认情况下,当进程超过其 cgroup 定义的资源限制时,操作系统将终止该进程。
结语
namespace 支持系统资源隔离,而 cgroup 则支持对这些资源进行精细的控制和限制。
了解更多关于 NGINX Unit 的信息并下载源码,亲自试用吧。
更多资源
请前往NGINX开源社区:
- 官网:nginx.org.cn



按点赞数排序
按时间排序


 点赞 6
点赞 6 浏览 6.4k点赞 1浏览 3.5k点赞 10浏览 4.9k
浏览 6.4k点赞 1浏览 3.5k点赞 10浏览 4.9k
 微信公众号
微信公众号 加入微信群
加入微信群

